Antwerp, 30 October 2020 14:00
In March, when COVID-19 hit several European countries hard, our team at Flanders Business School deployed a rather unconventional method to predict the occupation of ICU capacity and casualties, not just for Belgium but also for different European countries. Our predictions turned out to be very accurate and as we shared our findings with several epidemiologists and biostatisticians, our messages were being picked up by the authorities. You can read the story here or watch this informative video.
In September the numbers of infections and hospital occupancy started to rise again. By mid-October we started to rerun our model. Our main concern being the ICU occupation in Belgium.
Just like in spring we started with a large set (400.000) of potential curves (‘scenarios’). Next, we only retained those curves which fit with known, available data (from September 7th till October 25th).
When we analysed the results, we noticed two striking differences compared to our modelling efforts in March.
First of all, back then, even at the height of the crisis, our models showed very few scenarios with possible end states of 10.000.
This time, however, scenarios of 20.000 ICU beds present themselves as plausible (if no extra measures are being adopted).
Second, the maximum curves tend to be more accurate than the average curves. That is why we added a second criterion to our model: we only selected curves which correspond with recent real observations with 99% accuracy.
Below figure depicts the obtained curves (n=13) after model selection. The green dots reflect the observations we used to create the models; the red dots display the observed numbers afterwards.
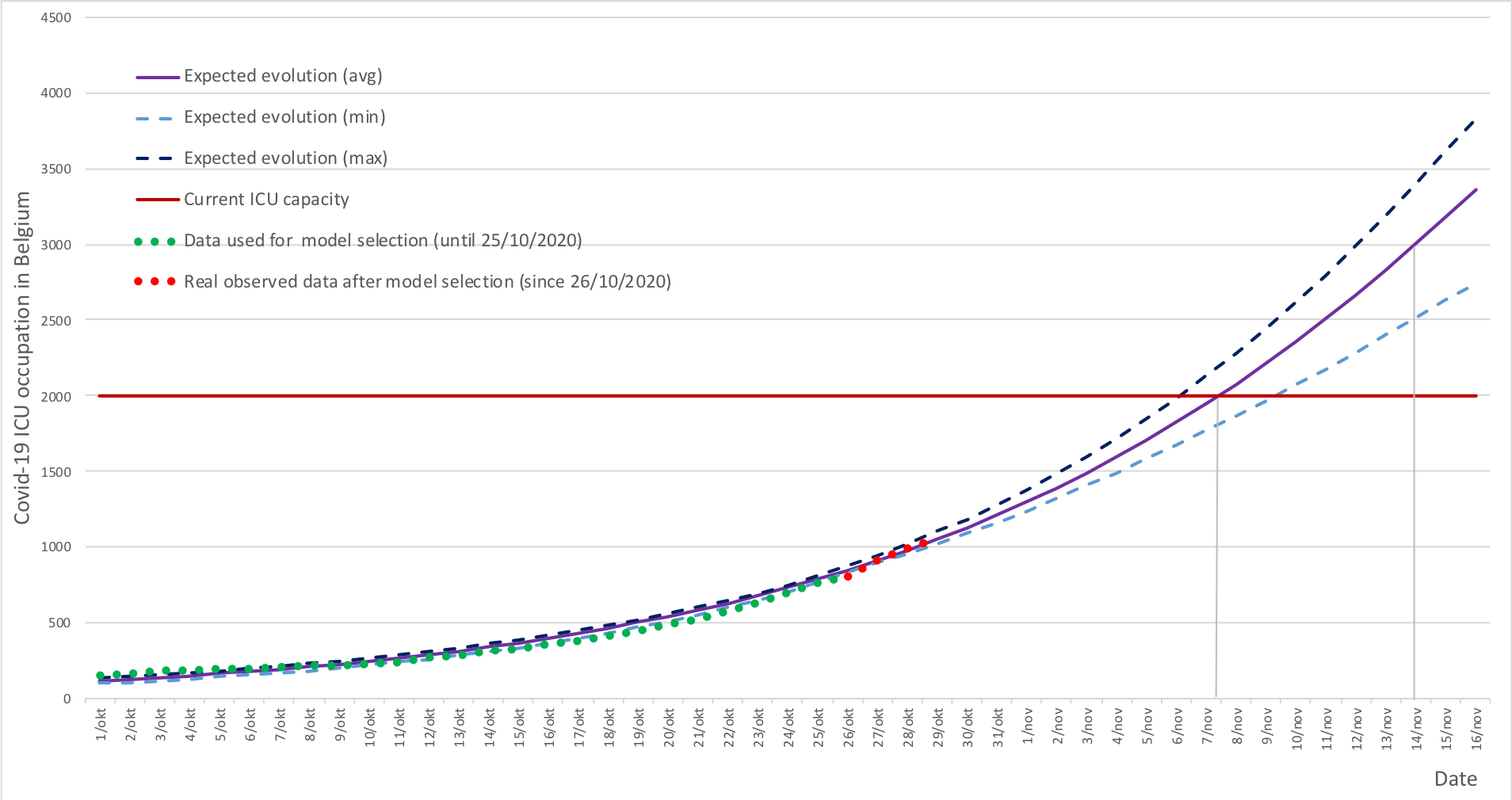
A bleak autumn
In table below you see the average predictions for the days to come.
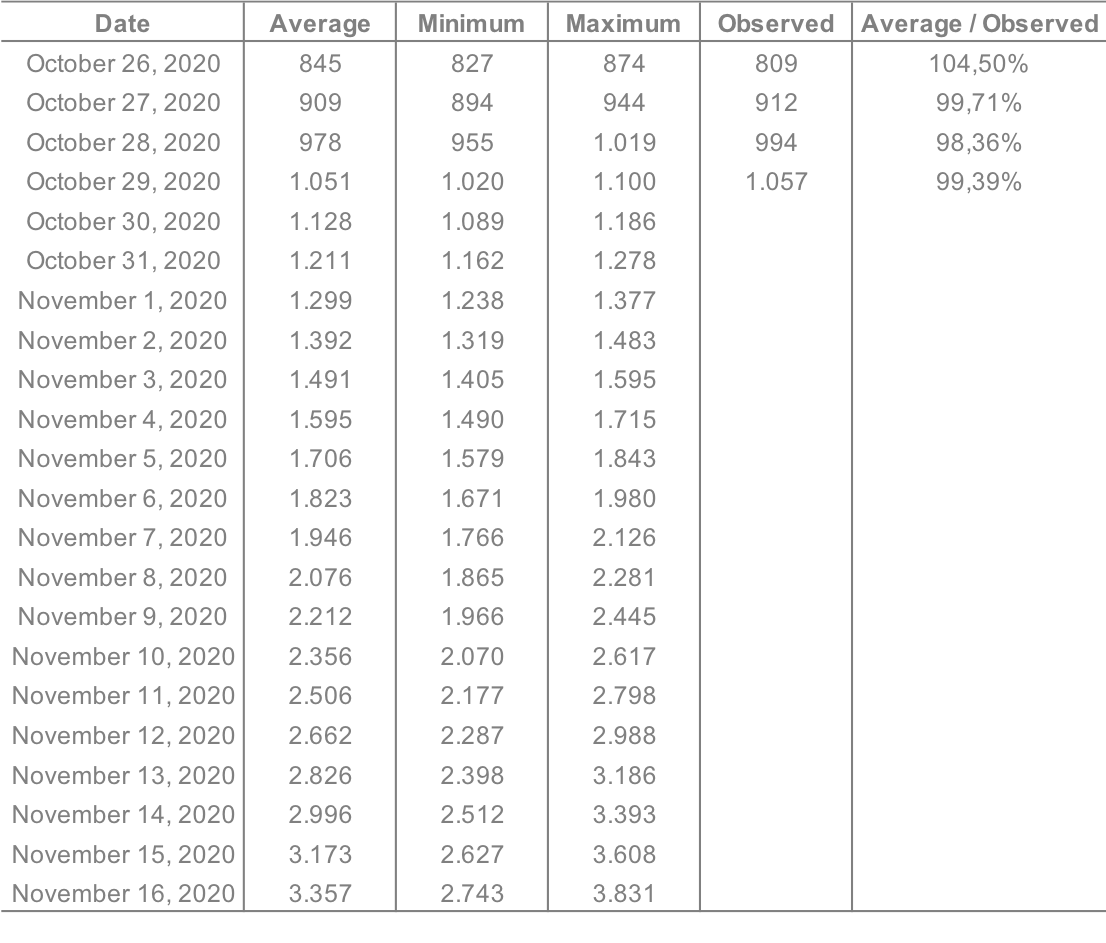
Our most recent available prediction (29 October) turned out to be 99,4% accurate.
If this trend is being confirmed the coming days, we will have 2000 ICU beds occupied on Friday 6 November, and on Friday 13th the need would be close to 3.000 beds.
We sincerely hope we are wrong this time.
You will be able to assess this the coming days by comparing our forecasts with the actual numbers reported.
Finally, we hope that by publishing these forecasts we contribute to a greater awareness (and more adequate behaviour) for all of us so that we can say on Monday 15th November: we did it. We managed to flatten the curve and move below the 3.000 level again.
Last but not least, to everyone working in the medical field, let us know if our models can be of any use. We will be glad to be of help.